Différents types d'attributs
Elément ou attribut ?
Nous avons vu :
– que l'on avait (pour l'instant : la question des entités nous conduira à reposer différemment la question) deux types d'informations ;
– que le premier type d'information était celui d'information pleine c'est-à-dire d'information se présentant comme telle ;
– que le deuxième type d'information était dérivé du premier.
Nous avons appelé « élément » le premier type d'information et « attribut » le deuxième type.
Appelons (dans le cadre de cette explication) :
– « information-élément » une information qui est un élément dans un fichier XML et qui donne donc lieu à une balise ;
– « information-attribut » une information qui est un attribut et qui sera donc donnée au sein d'une balise ouvrante.
Information-élément
Une information-élément est une information pleinement catégorisable (parce que c'est le cas ou parce que l'on a choisi cette solution)
Exemple : Exemple de "information-élément"
– dans un dialogue, chaque citation est une information-élément (c'est une information qui ne dépend de rien) ;
– dans une phrase, un groupe nominal est une information-élément (cette information ne dépend pas non plus d'autre chose).
Information-attribut
Une information-attribut :
dépend d'une information-élément ;
définit une propriété d'une information-élément ;
est associée à une information-élément.
Exemple : Exemple de "information-attribut"
Exemples :
– la durée d'une citation dépend de la citation ;
– la fonction d'un groupe nominal dépend du groupe nominal ;
– la langue de traduction d'un titre dépend du titre ;
– le registre de langue d'un exemple dépend de l'exemple.
Illustration des exemples précédents
1. La durée d'une citation dépend de la citation
Citation : « Il viendra demain »
Balise <cit> (citation) ; nom de l'attribut : durée ; valeur : 1 sec., 1 10e
Balisage : <cit duree=‟1s 1_1/10”>il viendra demain</cit>
2. La fonction d'un groupe nominal dépend du groupe nominal
Groupe nominal : « le chat » dans « le chat bois »
Balise <NP> (noun phrase) ; nom de l'attribut : fonction ; valeur : sujet
Balisage : <NP fonction=‟sujet”>le chat</NP>
3. La langue de traduction d'un titre dépend du titre
Titre : Before tomorrow (traduction de Avant demain)
Balise <tit> (titre) ; nom de l'attribut : lgue_trad ; valeur : anglais
Balisage : <tit lang_trad=‟anglais”>Before tomorrow</tit>
4. Le registre de langue d'un exemple dépend de l'exemple
Exemple : c'est foutu ! ; registre : vulgaire
Balise <exemple> ; nom de l'attribut : registre ; valeur : vulgaire
Balisage : <exemple registre=‟vulgaire”>c'est foutu !<exemple>
Les exemples qui précèdent illustrent des domaines différents :
une citation se trouve dans un corpus ou dans un article de dictionnaire ;
le balisage d'un groupe nominal se trouve dans un corpus ou dans un ouvrage de grammaire ;
un titre traduit se trouve dans une notice documentaire ;
un exemple se trouve dans un article de dictionnaire.
Tous les attributs utilisés jusqu'à maintenant ont deux propriétés :
ils sont formés d'une chaîne de caractères ;
ils ne font que caractériser un contenu catégorisé par une balise.
On les appellera « attributs CDATA ». CDATA signifie character data ou donnée caractères.
Il existe d'autres types d'attributs :
un attribut peut caractériser un exemplaire unique ;
un attribut peut correspondre à une entité non textuelle ;
un attribut peut correspondre à une série de chiffres.
Cependant, nous nous limiterons ici aux types d'attributs les plus fréquents dans les domaines qui nous intéressent.
Complément : Notons toutefois qu'on peut classer les attributs de la façon suivante :
Différents types d'attribut |  Les différents types d'attribut |
Certains de ces attributs sont particulièrement utiles dans des domaines comme la gestion de stocks ou le traitement de l'évolution boursière. Le caractère « langage à tout faire » de XML impose cette diversité.
Syntaxe : Rédaction de l'attribut
Les différents types d'attributs ne se perçoivent pas dans le document. On a toujours :
nom_de_l'attribut=‟valeur de l'attribut ”
Sauf le fait que, parfois, la valeur de l'attribut ne semble pas respecter les règles : si la valeur de l'attribut peut toujours comporter des signes diacritiques (mais pas le nom de l'attribut) comme les accents ou la cédille (é, ê, ë, á, ç, ę, ã, ñ, č, etc.), il ne doit pas, en général, comporter de blancs ni commencer par un chiffre.
Si le type d'un attribut ne se détecte que par d'éventuels blancs ou un chiffre à l'initiale de sa valeur, il n'en sera pas de même dans la DTD. C'est donc dans la DTD que le type d'attribut devient particulièrement important.
Mais le type d'attribut est aussi important pour le document : dans le document, le type d'attribut indiquera une fonction particulière.
Dans le document XML, on aura toujours :
<nom_de_l'élément nom_de_l'attribut=‟valeur de l'attribut”>
Dans la DTD, on aura (sur la même ligne) :
– le crochet ouvrant et le point d'exclamation : <!
– le mot clé ATTLIST
– le nom_de_l'élément caractérisé par l'attribut
– le nom_de_l'attribut
– le type_de_l'attribut
– le statut de l'attribut
– le crochet fermant : >
Exemple :
Exemple de la déclaration de l'attribut dans la DTD | 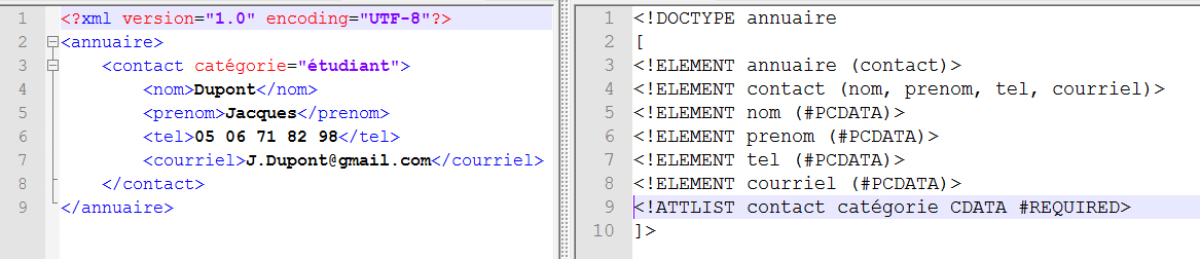 Déclaration de l'attribut dans la DTD |
Jusqu'à présent, nous avons vu :
– le nom de l'attribut
– une liste de types d'attributs
Avant de détailler un peu les types d'attributs, voyons quel peut être le statut d'un attribut. Ce statut comporte deux caractéristiques :
– le caractère obligatoire ou non de l'attribut,
– l'existence ou non d'une valeur par défaut de l'attribut.
Différents statuts des attributs | 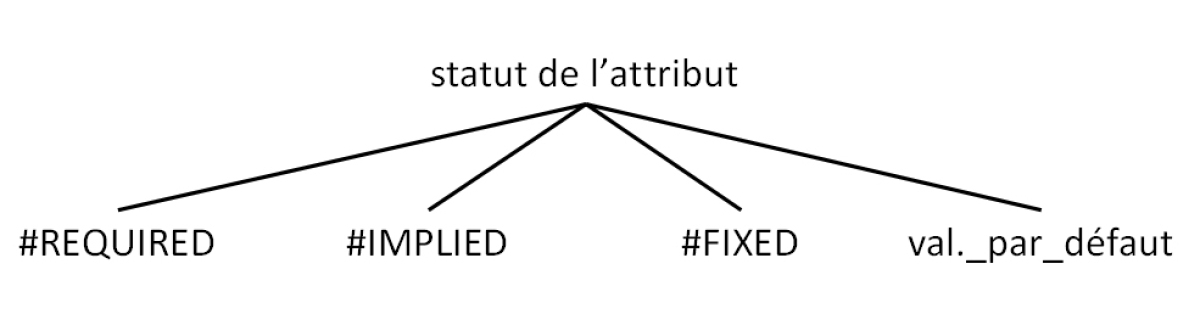 Statuts des attributs |
Reprenons les statuts possibles pour un attributs :
« #REQUIRED », l'attribut ne peut être omis ; dès lors qu'une balise donnée est présente dans le document, elle doit être accompagnée de l'attribut qui lui a été affecté dans la DTD ;
« #IMPLIED », l'attribut est facultatif ; une balise, à laquelle un attribut a été affecté dans la DTD, peut être accompagnée ou non de cet attribut dans le document ; de plus, il n'y a pas de valeur par défaut pour cet attribut lorsqu'il est absent ;
« #FIXED », l'attribut est facultatif mais, en cas d'omission dans le document, il reçoit la valeur par défaut fournie à la suite de « #FIXED » dans la DTD ;
« valeur_par_défaut », l'attribut reçoit la valeur par défaut en cas d'omission.
La différence entre « #FIXED » et « valeur_par_défaut » est la suivante : « #FIXED » permet « d'éviter » la valeur par défaut.
Nous pouvons maintenant décliner quelques types d'attributs.
Nous procéderons de la façon suivante :
– nous indiquerons le type d'attribut décrit ;
– nous le caractériserons de façon informelle ;
– nous donnerons la formulation dans le document ;
– nous donnerons la formulation dans la DTD.
Mais nous ne préciserons pas le statut de l'attribut car cela dépend des cas traités. Nous indiquerons seulement statut (en italique) dans la formulation dans la DTD.
Le type ID
Le type d'attribut ID permet d'identifier un objet. On aura donc, dans le document, un attribut ID unique à chaque occurrence de la balise affectée de cet attribut. Dans une gestion de stock, cet attribut permet de caractériser chaque objet du stock quand il existe différents exemplaires de cet objet.
<item code=‟T001”>table de salon ronde</item>
<item code=‟T125”>table du cuisine 2,50m x 1,75</item>
<item code=‟R801”>étagère l=2,50m ; h=1,80m montants tubes</item>
<item code=‟R463”>bibliothèque chêne clair portes vitrées l=1,50m ; h=1,70m</item>
Le document contenant cet extrait permet aussi bien de gérer le stock que d'éditer un catalogue.
Dans la DTD, un attribut de type ID, utilisé dans l'extrait précédent d'un fichier de gestion de stock, sera déclaré de la façon suivante :
<!ATTLIST item code ID statut>
Dans cette déclaration, on reconnaît :
– le nom de l'élément : item
– le nom de l'attribut : code
– le type de l'attribut : ID
A quoi peut servir un attribut ID dans notre cas ?
Premier exemple.
Dans un dictionnaire, on a des renvois (qui seront, dans un fichier HTML, les points de départ d'hyperliens). Ce point de départ doit être identifié. On pourra utiliser un attribut ID.
Deuxième exemple
Dans un corpus, on veut identifier chaque intervention de chaque interlocuteur. On pourra avoir, par exemple, dans le document :
<citation locuteur=‟Marie” intervention=‟16”
Dans cet exemple, le premier attribut (locuteur) est de type CDATA, le second, de type ID, donne le numéro de l'intervention de Marie.
Le type IDREF
Un attribut IDREF correspond à un attribut ID. Prenons l'exemple d'une aile de voiture, elle correspond à un type de voiture. On pourrait ainsi avoir :
<voiture code=‟Mod304”>5 portes ; peinture bleue</voiture>
<aile code_piece=‟av_g_112” vehicule=‟Mod304”>bleue</aile>
L'attribut de voiture est un attribut ID. Le premier attribut de aile est un attribut CDATA, le second un attribut IDREF.
Dans la DTD, on aura :
<!ATTLIST voiture code ID statut>
<!ATTLIST aile code_piece ID statut vehicule IDREF statut>
Dans un dictionnaire, un attribut IDREF permet de désigner le point d'arrivée d'un hyperlien de renvoi. Dans un corpus, un attribut IDREF permet d'associer une prise de parole à une autre, par exemple « question-réponse ».
Si l'on voulait associer une question à plusieurs réponses possibles, on utiliserait un attribut IDREFS pour la question.
Le type NMTOKEN
La valeur d'un attribut NMTOKEN commence par un chiffre. Un tel attribut est donc tout indiqué pour noter un ISBN. Exemple :
<livre ISBN=‟2-114-00089”>Une voiture pour Dallas</livre>
(bien entendu, nous avons abrégé la référence ; elle devrait comporter d'autres balises et, éventuellement, d'autres attributs.)
Dans la DTD, on aura :
<!ATTLIST livre ISBN NMTOKEN statut>
Nous avons déjà vu un exemple de NMTOKEN dans un corpus :
Citation : « Il viendra demain »
Balise <cit> (citation) ; nom de l'attribut : durée ; valeur : 1 sec., 1 10e
Dans le document, on aura :
<cit duree=‟1s 1_1/10”>il viendra demain</cit>
et dans la DTD :
<!ATTLIST cit duree NMTOKEN statut>
Remarque :
A priori, la différence que nous avons faite entre :
catégorie / balise / élément d'une part
et :
propriété / caractéristique / attribut d'autre part
est parfaitement claire. Mais il y aura des zones de recouvrement. Ainsi, avons-nous traité le numéro ISBN comme un attribut alors qu'on pourrait aussi le traiter comme une catégorie pleine.
ISBN attribut (cf. ci-dessus) :
<!ATTLIST livre ISBN NMTOKEN statut>
<livre ISBN=‟2-114-00089”>Une voiture pour Dallas</livre>
ISBN catégorie :
<livre><titre>Une voiture pour Dallas</titre><ISBN> 2-114-00089</ISBN></livre>
Dans ce cas, le choix sera pragmatique : on utilisera la solution la plus pratique.
Nous n'avons pas vu la notion d'attribut dans tous les détails. Nous avons seulement envisagé quelques cas en privilégiant la technique d'écriture et en essayant d'illustrer les usages possibles de tel ou tel type d'attribut.
Mais l'attribut n'est pas le seul complément à la notion de balise-élément. L'attribut avait pour objectif d'essayer de formaliser la notion « propriété de ». Un autre problème demeure : tous les documents ne sont pas des documents-textes. Nous aurons donc besoin d'autres outils.
C'est pourquoi nous allons maintenant passer à la notion d'entité.
