

Champs connexes et applications XML
Présentation rapide des champs connexes et applications XML
Comme nous venons de le voir, la langage XML s'inscrit au sein d'un contexte qui est marqué par un positionnement qui évolue au sein du et par rapport au numérique. Nous allons esquissé une représentation globale de ce contexte qui n'est pas stabilisé :
la gestion électronique des documents (GED),
la représentation des connaissances,
la text encoding initiative (TEI),
la linguistique de corpus,
la folksonomie,
le Dublin Core,
l'open archives initiative (OAI),
les Digital Humanities,
le web sémantique.
Tous ces domaines peuvent être hiérarchisés selon les étapes du processus, selon la couverture qu'ils assurent.
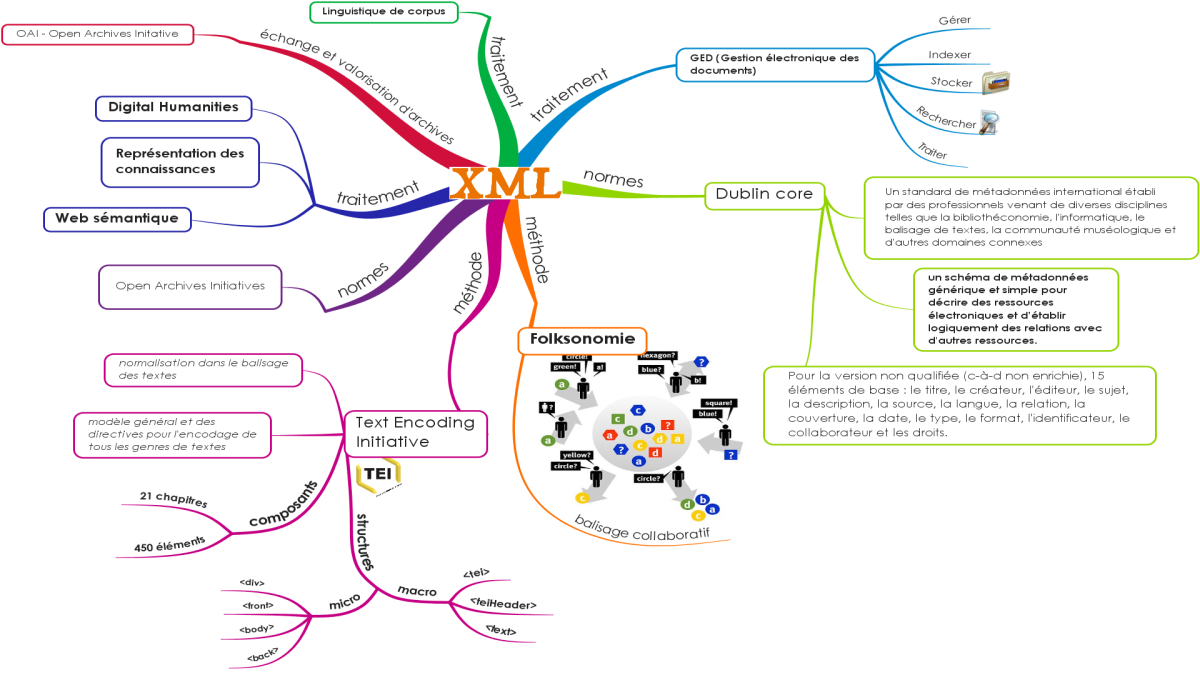
Complément : La Gestion électronique des documents (GED)
La Gestion électronique des documents (GED) représente un premier état du numérique : quels formats numériques pour les documents ? pour quelles fonctionnalités ? pour quelle diffusion? comment passer d'un format à un autre ? comment diffuser les documents numériques ? comment les normer en vue d'une diffusion plus large et d'une compréhension plus homogène ?
Mais ces questions étaient précédées par d'autres puisqu'il s'agissait de passer d'un monde « papier » au monde « électronique ». Il faut donc acquérir (passer du papier au numérique), classer, stocker, indexer, structurer la consultation. Ce travail de transformation porte sur des volumes papier très importants et il y a deux types de transformation :
– transformation des documents, papier → numérique ;
– transformation des pratiques (on traite le numérique comme on traite le papier.)
Cette transformation des documents et des pratiques a entraîné l'évolution des technologies. Scanner un document au format image ne permet pas de réutiliser le contenu en le prélevant et en le modifiant pour l'adapter au nouveau contexte. On a donc produit des logiciels d'OCR (optical character recognition) afin de reconstruire des chaînes de caractères manipulables dans les documents électroniques (à l'époque, on ne disait pas encore numériques) obtenus.
Dans le domaine public, on a longtemps conservé les archives papier après les avoir converties au format électronique, pour deux raisons, d'une part seul le papier continuait à « faire preuve » (ou « être probant »), d'autre part par manque de signature électronique recevable.
La GED représente donc une phase dans l'évolution de la numérisation. Cette phase a encore son actualité :
– si, conceptuellement, une transition peut ne prendre que quelques années, dans les faits, la même transition va durer parfois quelques dizaines d'années ; il faut donc organiser cette transition ;
– tous les pays n'évoluent pas à la même allure, mais on ne peut pas non plus exporter simplement une ancienne phase ; il faut donc construire de nouvelles « phases GED » pour les pays en voie de développement ;
– les questionnements de la GED offrent une sorte de modélisation pour d'autres questionnements.
La GED suppose un workflow, une chaîne de validation de la séquence d'opérations à effectuer par une ou des personnes.
Sur le plan des usages, la situation évolue et l'on attend beaucoup (peut-être à tort) du passage à la génération des digital natives qui auront une vingtaine d'années en 2015/2020.
Sur le plan des contenus, les gabarits (templates) de documents sont de plus en plus intriqués et l'on confond de plus en plus de ce fait GED et CMS (Content Management System).
La GED apparaît ainsi comme une entreprise de « dématérialisation des contenus ».
La GED a permis de s'interroger, et donc de progresser, sur la gestion collective et collaborative des documents :
– partager suppose des normes communes acceptées mais aussi, et surtout, utilisées de façon identique ;
– les documents (on dit aujourd'hui ressources) peuvent être indexés de deux façons :
par type, on associe aux documents des métadonnées (des données qui caractérisent le document dans son ensemble) ;
par concepts ou mots-clés, on associe à chaque document des « descripteurs de contenu ».
Complément : La représentation des connaissances
Représenter les connaissances, c'est offrir un mode d'accès aux connaissances nécessaires pour tel domaine en leur associant des formats différents (textes, images, vidéos, graphes conceptuels, réseaux sémantiques, schémas d'actions, etc.). La représentation des connaissances n'est donc pas une tentative de rassemblement du savoir humain. C'est avant tout la recherche d'une base pour la prise de décision ou pour la modélisation des acquis dans tel champ.
La notion de représentation des connaissances a d'abord été une notion d'intelligence artificielle et les systèmes-experts l'ont mise en forme au cours des années 1980. Un système-expert, c'est :
une base de connaissances structurées et formalisées (la structure la plus simple étant l'arborescence) ;
un ensemble de règles permettant de corréler les données d'un problème et le contenu de la base de connaissances.
Une base de connaissances est forcément liée à un champ du savoir (médecine, géologie, etc.). Le problème est formulé par le « client ». Une interface adéquate permet au client de n'avoir pas à se plier à un jeu de contraintes formelles pour formuler les données de son problème.
La notion de représentation des connaissances mobilise donc plusieurs facteurs :
un langage adéquat pour formuler les connaissances (c'est souvent un langage logique de type calcul des prédicats) ;
une notion d'environnement (les connaissances sont référencées à un champ du savoir, les inférences sont référées à telles ou telles pratiques de raisonnement).
Il faut ajouter un autre facteur. Dès lors que l'on n'est plus dans la résolution de problème (système-expert), il faut des outils formels et cognitifs (c'est-à-dire adaptés à la cognition humaine) pour représenter le savoir de tel champ.
De même qu'une carte représente un territoire mais n'est pas ce territoire, une représentation de connaissances n'est pas une somme de connaissances, ni une représentation du « réel ». Il faut donc modéliser les connaissances. C'est le rôle d'une « ontologie », système de concepts qui relient des objets à ces concepts associe des propriétés aux concepts (partagés alors par tous les objets) et aux objets (propriétés particulières). Il faut donc travailler sur la notion de définition : on remarque qu'une définition de dictionnaire ne rend pas forcément l'usage d'un mot facilement partageable et stable dans son utilisation. Il faut aussi une syntaxe et une sémantique qui fournissent des expressions stables et facilement interprétables par les usagers.
Le domaine de la représentation des connaissances est donc un domaine vaste qui évolue et est appelé à évoluer.
Complément : La Text Encoding Initiative (TEI)
La Text Encoding Initiative (TEI) est une entreprise de normalisation qui vise à définir un format de création, de stockage et d'échange de documents-ressources recourant au langage XML en le spécifiant à la fois au niveau général et au niveau des différents domaines (recueil et transcription de données orales, édition de manuscrits, recueil et échange de corpus, etc.). On distingue alors le niveau physique (fichier ayant un certain format indiqué par l'extension du nom de ce fichier) et le niveau logique (document / ressource). On peut ajouter un troisième niveau, le niveau conceptuel (type de document) mais cette question demeure difficile à résoudre.
La TEI (dont l'acronyme est parfois rendu par Text Encoding Interchange, selon l'interprétation du mot initiative qui peut renvoyer au démarrage d'une action ou à l'action elle-même) est donc avant tout orientée vers le partage des ressources.
Le consortium TEI-C édite des Guidelines. En décembre 2011, la version revue de la version 5 a été publiée :
www.tei-c.org/release/doc/tei-p5-doc/en/Guidelines.pdf
Le fait que la TEI tienne compte des différents domaines d'application entraîne une certaine modularité. Il faut aussi conserver une certaine liberté pour l'encodeur du document et donc définir ces espaces de liberté.
La TEI propose un type de DTD et de header minimal. Cela permet de constituer une sorte de superstructure partageable par tous et qui donne de grandes lignes de structuration formant des repères.
La TEI joue ainsi bien son rôle de consortium de référence qui offre des recommandations structurantes mais non aliénantes.
Complément : La linguistique de corpus
La linguistique de corpus n'est pas une nouvelle théorie linguistique. C'est plutôt une nouvelle façon de faire de la linguistique. Certes, dès lors que l'on met en avant les corpus de données, la théorie sous-jacente tend à être plus empiriste que rationaliste. Toutefois l'appellation linguistique de corpus ne cherche pas simplement à renouer avec une linguistique de type distributionnaliste (qui était la théorie de référence entre la fin des années 1920 et le début des années 1950 aux Etats-Unis).
Les années 1950 ont été marquées, en linguistique, par l'émergence de la grammaire générative qui se voulait rationaliste, fondée sur le sentiment linguistique et formelle, la version actuelle de la grammaire générative étant la théorie minimaliste. D'autres théories formelles suivront (HPSG, TAG, etc.).
Les années 1980 verront aussi l'émergence des linguistiques cognitives qui sont aussi peu portées sur la notion de corpus.
Quelle peut donc être la motivation de l'émergence de la linguistique de corpus au début des années 1990 ?
Le langage SGML, qui préfigure (plus que HTML) le langage XML, a porté avec lui l'espoir d'une catégorisation assez fine des données et de la possibilité d'échanger des données de grand volume partageables grâce à ces catégorisations.
Ce qui favorise l'interopérabilité et le partage, c'est l'explicitation scrupuleuse des normes utilisées. Dès lors que cette explicitation a lieu, on peut chercher à transformer un objet selon ses normes en un objet équivalent mais conçu selon d'autres normes.
Le langage XML a renforcé cette tendance et linguistique de corpus est un peu devenu synonyme de balisage. La linguistique de corpus conjoint donc empirisme et un certain formalisme.
Complément : La folksonomie
Le terme folksonomie désigne le balisage manuel.
L'intérêt de cette notion réside dans l'écart entre balisage automatique et balisage manuel. D'une part, un balisage manuel peut servir d'entraînement à un balisage automatique (le logiciel de balisage « apprend » à partir de fichiers balisés manuellement). Mais le balisage manuel permet aussi de catégoriser des données que l'on ne saurait pas catégoriser automatiquement. Dans ce dernier cas, il est préférable de procéder à un double balisage manuel afin d'éviter les idiosyncrasies.
Une application raisonnée de la folksonomie peut nous donner des informations sur le fonctionnement de la catégorisation cognitive dans tel groupe humain ou tel groupe social. C'est alors la récurrence d'un balisage identique qui est importante.
Complément : Dublin Core
En 1995, à Dublin, Ohio, USA, un groupe de travail s'est réuni pour définir un registre de métadonnées partageables par les instances gouvernementales étatsuniennes (ministères de la défense, de la justice, de la santé, etc. Cela a débouché sur un groupe de travail international : le Dublin Core Metadata Initiative (DCMI). La base du Dublin Core se compose de 15 éléments :
titre (title, titre principal du document, métadonnée),
créateur (creator, personne, organisation à l'origine de la rédaction, métadonnée),
sujet (subject, métadonnée ou mots-clés),
description (description, résumé, table des matières, métadonnée),
éditeur (publisher, personne ou organisation à l'origine de la publication),
contributeur (contributor, personne ou organisation ayant contribué à l'élaboration, un élément contributeur par contributeur),
date (date, date d'un événement, il peut donc y en avoir plusieurs),
type de ressource (type, genre de contenu, cet élément donne lieu soit à un espace de liberté soit à une « théorie » des genres qui doit alors être partagée; on retrouve là une question bien connue en sciences du langage, celle des genres discursifs),
format (format, format physique du document),
identifiant (identifier, ce peut être une URI, un ISBN, etc., l'important est de partager les identifiants et d'utiliser un système de référencement très précis),
source (source, source du document décrite formellement),
langue (language, langue du document),
relation (relation, liens précis avec d'autres documents),
couverture (coverage, couverture spatiale (pays, continent, etc.) ou temporelle (époque),
droits (rights, copyright, droits de propriété, droits patrimoniaux, droits de reproduction, etc.).
Ces différents éléments recoupent des problématiques comme celles des genres discursifs (cf. ci-dessus), des relations entre documents (citations, renvois intertextuels, éléments intertextuels implicites), des droits sur l'internet mais aussi de la licence GNU-GPL qui gère généralement (à différents degrés) les documents dits open source.
A côté du « Dublin Core simple », existe le « Dublin Core qualifié ». Il s'agit de prendre en compte les besoins de groupes spécifiques et d'harmoniser leurs codages.
Complément : Open Archives Initative
Objectif : valoriser et échanger des archives numériques en permettant de moissonner des métadonnées sur des sites de fournisseurs de données.
Différents appels internationaux (Budapest, Berlin) depuis 2001 ont cherché à promouvoir les archives ouvertes.
Concept d'archive ouverte : la notion d'archives ouvertes appartient au mouvement de l'open source mais open ne veut pas dire gratuit pour deux raisons, d'une part une édition peut générer des coûts indépendants de l'objet édité (support par exemple), d'autre part parce qu'il a bien fallu payer des salaires pour que le travail soit réalisé et donc soit des mécènes privés soit le recours aux fonds publics.
Moteur de recherche : BASE développé par l'Université de Bielefeld (http://www.base-search.net).
Protocole : OAI-PMH (Open Archives Initiative Protocol for Metadata Harvesting), protocole fondé sur XML et le Dublin Core
L'objectif est de faciliter la publication et la gestion des documents scientifiques numériques par les établissements universitaires.
Complément : Digital Humanities
Le recours au numérique conduit à une nouvelle approche des documents ou ressources. La capacité de traiter des données en grand nombre, de recueillir de grands corpus, de sélectionner et comparer rapidement des données, mais aussi les effets induits sur les comportements humains, tout cela produit une problématique nouvelle, les Digital Humanities ou Humanités numériques, renouant avec un concept parfois un peu oublié, celui d'Humanités (on notera le pluriel obligatoire). Les digital humanities constituent donc une double problématique qui porte à la fois sur les usages et sur la gestion des contenus.
Cette problématique est la problématique actuelle (2012) et représente un défi à la fois international et conceptuel dans un monde (les sciences humaines et sociales, SHS) qui est, traditionnellement, plutôt divisé en groupes ne partageant pas toujours données et méthodologies.
Complément : Le web sémantique
La structure initiale du web était marquée par :
une structure hiérarchique (client qui sollicite une information / serveur qui détient l'information) ;
un langage de représentation des données (HTML) ― ou langage d'édition de pages web ― limité aux opérations d'affichage.
Dans ce contexte, tous les documents sont faits pour être lus par un agent humain extérieur.
Le « web 2 » a apporté une évolution en privilégiant non plus les relations verticales (et donc hiérarchiques comme dans le « web 1 ») mais les relations transversales (donc complémentaires ou collaboratives).
La notion de web sémantique se greffe sur la notion de web 2 tout en ajoutant l'idée de signifiance du balisage (dont nous avons déjà abondamment parlé). C'est donc une technologie XML.
En guise de conclusion...
Le panorama que nous venons d'esquisser montre que le contexte actuel est en pleine évolution. Il apparaît aussi qu'il est fortement marqué par le langage XML.
Ce contexte a des aspects techniques (on s'en doute depuis un certain temps) mais aussi sans doute sociologique. Il aura aussi des aspects théoriques et conceptuels.




